
Friday
31 OctCrawl Budget Explained: Why Google Might Not Be Indexing All Your Pages
Are you frustrated that your new content sits invisible in Google Search Console while competitors’ pages get indexed within days?
Well…you’re not alone in this struggle. Business owners publish valuable content and wait weeks, only to find pages stuck in “discovered – currently not indexed” status. One expert says, “submit your XML sitemap,” another says, “wait for Google’s crawlers,” and meanwhile, you’re losing traffic to sites that figured it out.
Here’s what’s happening. Google assigns every site a crawl budget, and if yours is wasted on broken links, duplicate pages, or unnecessary pages, your important URLs never get the attention they deserve. Because search engines can’t index pages they haven’t crawled yet.
At H-Mag, we’ve helped Brisbane businesses fix crawl budget issues using white-hat SEO strategies. In this guide, we’ll show you how to check if crawl budget affects your site, identify what’s wasting crawl budget, and optimise crawl capacity so search results include your best content.
Ready to learn more about crawl budget SEO? Let’s get started.
What Is Crawl Budget (And Does Your Site Even Need to Worry)?
Crawl budget is the number of pages Google will crawl on your site within a given timeframe. Most sites under 1,000 pages don’t need to worry about it, but growing and larger sites should pay attention.
Let’s clear up the confusion without the technical jargon.
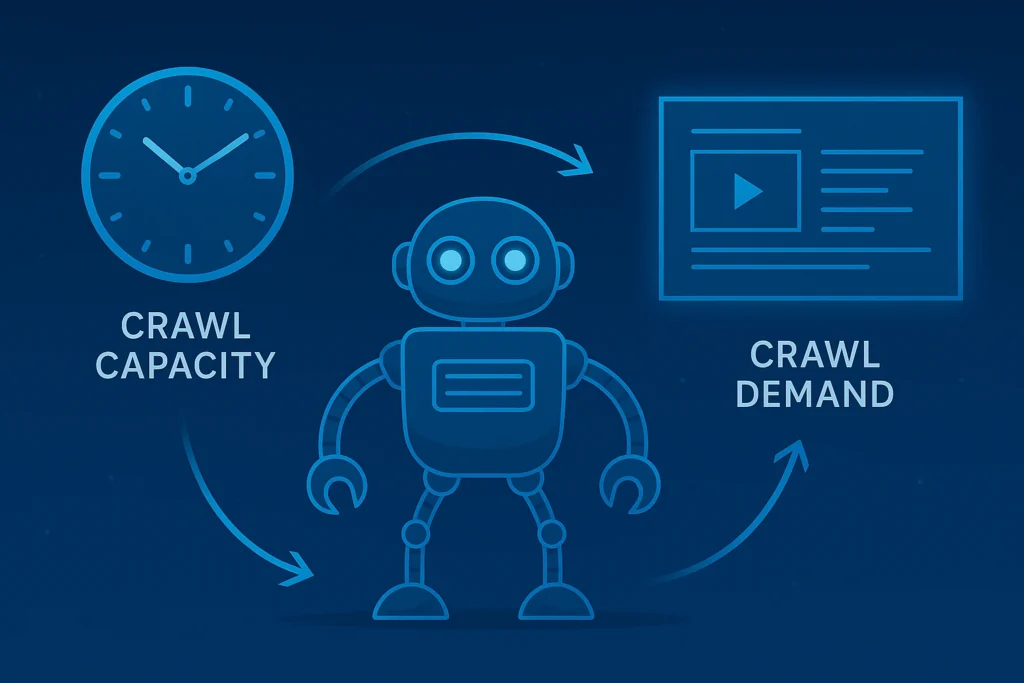
Think of crawl budget as Google’s time allowance for visiting your site. Search engines have limited resources, so they assign each website a specific amount of crawling time. This budget depends on two main factors: crawl capacity (how fast your server responds to Google’s crawlers) and crawl demand (how much Google wants to crawl your content based on popularity and freshness).
Now, before you panic and start optimising everything, here’s the question you need to answer: Does your site size even require crawl budget optimisation?
- Small sites (under 1,000 pages): You’re probably fine. Google Search Console data shows search engines can crawl these sites efficiently. Your indexing errors likely come from other issues, like noindex meta tags or server errors, not crawl budget problems.
- Growing sites (1,000-10,000 pages): Watch for warning signs. If new pages take weeks to appear in search results, or you see “discovered – currently not indexed” errors piling up in your index coverage report, crawl budget might be your bottleneck.
- Larger sites (10,000 pages): E-commerce platforms, news sites, and content-heavy blogs need crawl budget optimisation. With this many pages, Google crawls only a fraction daily, meaning important pages might wait months before getting indexed.
Here’s a simple test you can run right now. Open Google Search Console, go to Settings, then check your crawl stats. Calculate this: your total site pages divided by average pages crawled per day. If that number is higher than 10, you’ve got a crawl budget issue that needs attention.
So what happens when the crawl budget runs out? Google’s crawlers stop visiting your site until the next crawl cycle. And what about your brilliant new product page?
It sits in the indexing queue while your competitors’ pages get indexed and start ranking. That’s lost traffic and lost revenue while you wait.
If you’re in that second or third group, let’s learn what’s eating up your crawl budget.
Common Crawl Budget Killers Hiding on Your Site
Your crawl budget is leaking, and the usual suspects might surprise you.
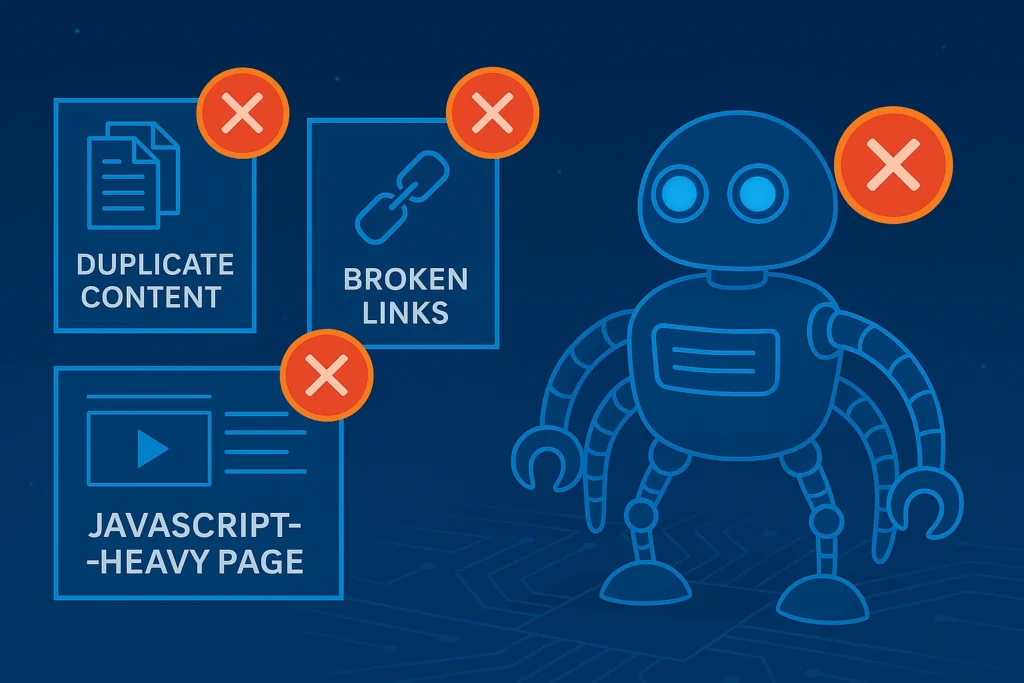
The three biggest crawl budget killers are duplicate content, broken links with redirect chains, and JavaScript-heavy pages. Most crawl budget waste comes from pages Google shouldn’t be crawling at all.
While you’re waiting for important pages to get indexed, search engines are burning through your crawl capacity on content that adds zero value to your search results.
Duplicate Content Draining Resources
This is the silent killer on most sites. When you create product filters, sorting options, or session IDs, each variation generates a new URL. Google sees these as separate pages and crawls every single one.
Have a look at this real example: an e-commerce site selling shirts creates URLs for colour filters (blue, red, green), size filters (small, medium, large), and price sorting (low to high, high to low).
One product now has 50 different URLs, all showing the same content. Google’s crawlers visit each URL, discover they’re duplicate pages, and your crawl budget disappears on identical content.
The index coverage report in Google Search Console flags these as “duplicate or alternate pages,” but by then, the damage is done. You need a proper canonical tag on these alternate pages, telling search engines which version is the main one worth indexing.
Broken Links and Redirect Chains
Every 404 error on your site wastes crawl budget. Google discovers a URL through internal links or your XML sitemap, sends crawlers to check it, and gets a “page not found” response. That’s wasted effort on a bad or empty URL that could’ve been spent on pages Google should be indexing instead.
Redirect chains are even worse. When you redirect non-www to www, then http to https, that’s two separate crawl requests for one page. Multiply that across your entire site, and you’re doubling the time Google needs to reach your content. The crawl rate slows down, fewer pages get indexed, and your new pages sit in the queue.
Check your server logs or Google Search Console’s page indexing report regularly. If you see hundreds of server error codes (500s) or broken links, you’re throwing away crawl budget on URLs Google can’t even access.
JavaScript-Heavy Pages
This catches people off guard. When search engines crawl simple HTML pages, it’s a two-step process: crawl and index. But JavaScript pages require three steps: crawl, render, and then index. Google’s crawlers need to execute your JavaScript code, wait for content to load, then process everything for indexing.
That rendering step uses significantly more resources from your site’s crawl budget. Even medium-sized sites with JavaScript frameworks can hit crawl capacity limits quickly.
The page experience table in Google Search Console might show your pages loading fine for users, but Google’s crawlers are struggling with the same page behind the scenes.
Some of your pages indexed might be missing JavaScript-generated content entirely because Google ran out of crawl budget during the rendering phase.
Now that you know what’s wrong, it’s time to know how to fix it.
Quick Fixes You Can Do Today (No Developer Required)
Here’s the relief you’ve been waiting for. Most crawl budget problems have simple fixes you can handle yourself today.

The difference between sites that waste crawl budget and those that use it wisely comes down to prioritisation. You need to separate urgent fixes from long-term strategies, then guide Google’s crawlers toward your most important URLs.
What to Fix First
| Action | Why It Matters | Where to Do It |
| Check Index Coverage Report | See which pages aren’t indexed and why | Google Search Console → Pages → Why pages aren’t indexed |
| Block low-value pages | Stop wasting crawl budget on login pages, admin areas, and thank you pages | robots.txt file on your server |
| Fix broken links | Remove 404 errors from Google’s crawl queue | Use URL Inspection Tool in Search Console |
| Add/update XML sitemap | Tell search engines which important pages to crawl first | Submit in Google Search Console → Sitemaps |
Let’s talk about two tools that confuse most people but solve duplicate content issues instantly.
The noindex meta tag keeps pages live on your site but tells search engines “don’t add this to your index.” This works perfectly for thank you pages, internal search results, or filtered product pages that create duplicate content.
You’re hiding these pages from search results, not from users. Google saves crawl budget for pages that deserve to rank.
The canonical URL tag is different. When you have multiple pages showing the same content (like product variations or printer-friendly versions), the proper canonical tag tells Google “this is the main version worth indexing.”
Other search engines see all the alternate pages but only index the one you’ve marked as canonical. This prevents Google from wasting crawl budget on crawling multiple versions of identical content.
Here’s what most site owners miss: Google Search Console has a “Validate Fix” button under the indexing report. After you fix indexing errors, click “Request Indexing” through the URL Inspection Tool. This asks Google to crawl those specific pages sooner rather than waiting for the next scheduled crawl request.
But let’s be realistic about timelines. When you optimise your site’s crawl budget today, don’t expect your pages indexed to jump overnight.
Google needs to recrawl your site, process the changes, and verify your fixes work. You’ll typically see improvements in how many pages get indexed within two to four weeks.
The crawl stats in Search Console will show increased crawl requests on important pages and fewer on unnecessary pages.
One more thing about XML sitemaps. They’re submission forms and navigation guides combined. Your XML sitemap tells Google which pages changed recently, which ones are most important to your site, and how often content updates.
Sites that keep their XML sitemaps current with accurate priority settings see better crawl efficiency because they’re helping search engines make smarter decisions about where to spend crawl capacity.
If you’re running a larger site with thousands of indexed pages, you might need to split one massive XML sitemap into smaller, organised sitemaps. Google processes these faster, and you can track crawl performance for different sections of your site separately.
When to Optimise (And When to Move On)
So, the bottom line is: crawl budget optimisation is truly important for sites over 1,000 pages, but smaller sites should focus elsewhere.
Check your crawl stats in Google Search Console first. Divide your total pages by the average crawl rate. If it’s below 10, crawl budget isn’t your problem. Work on content quality instead.
For growing businesses, these fixes help search engines index pages efficiently. That’s white-hat SEO done right. The sites we work with in Brisbane see the best results when they fix duplicate content, broken links, and server errors together.
Need help with technical SEO issues? Drop us a line at H-Mag. We handle the complex stuff so you can run your business.